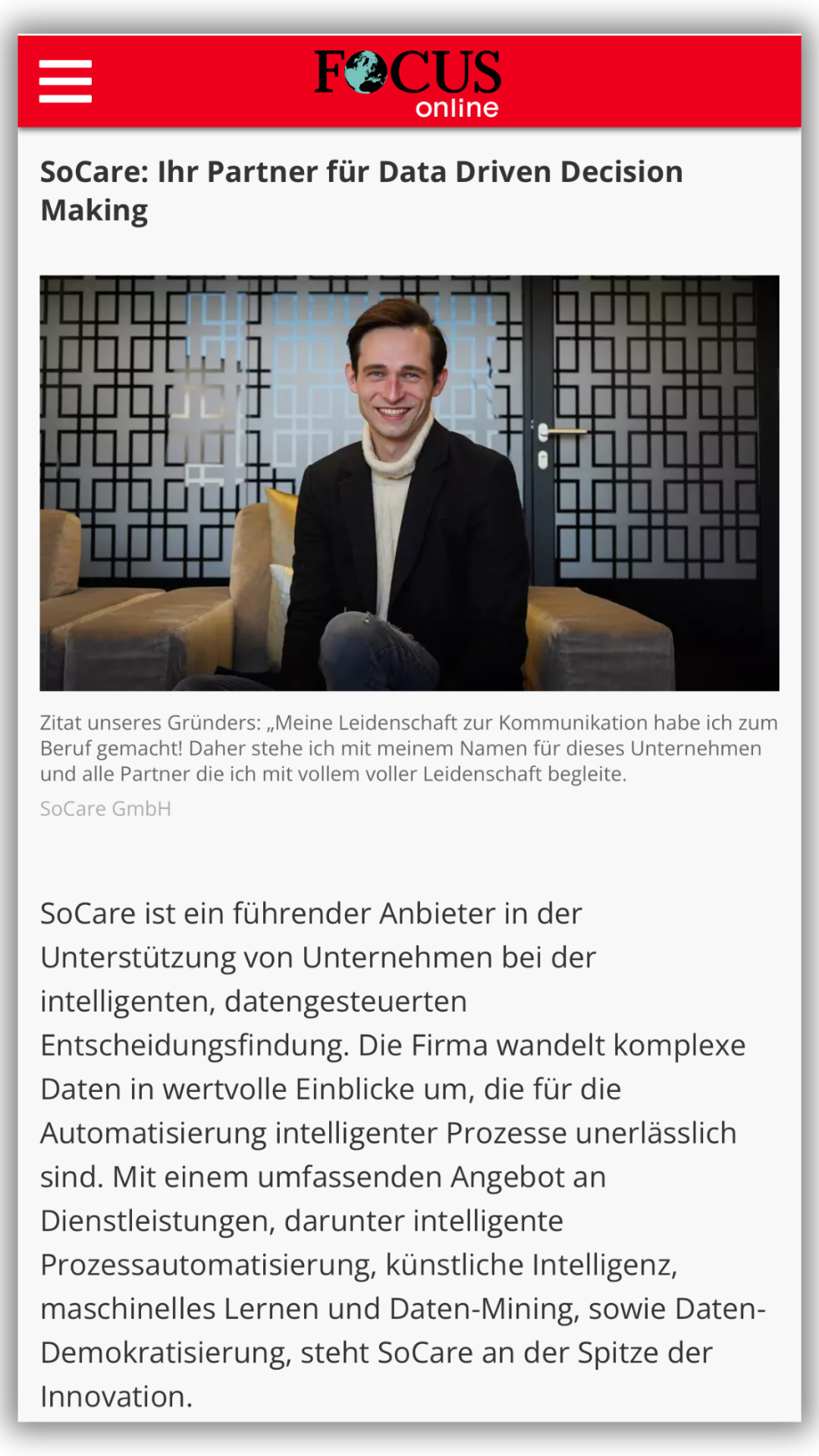
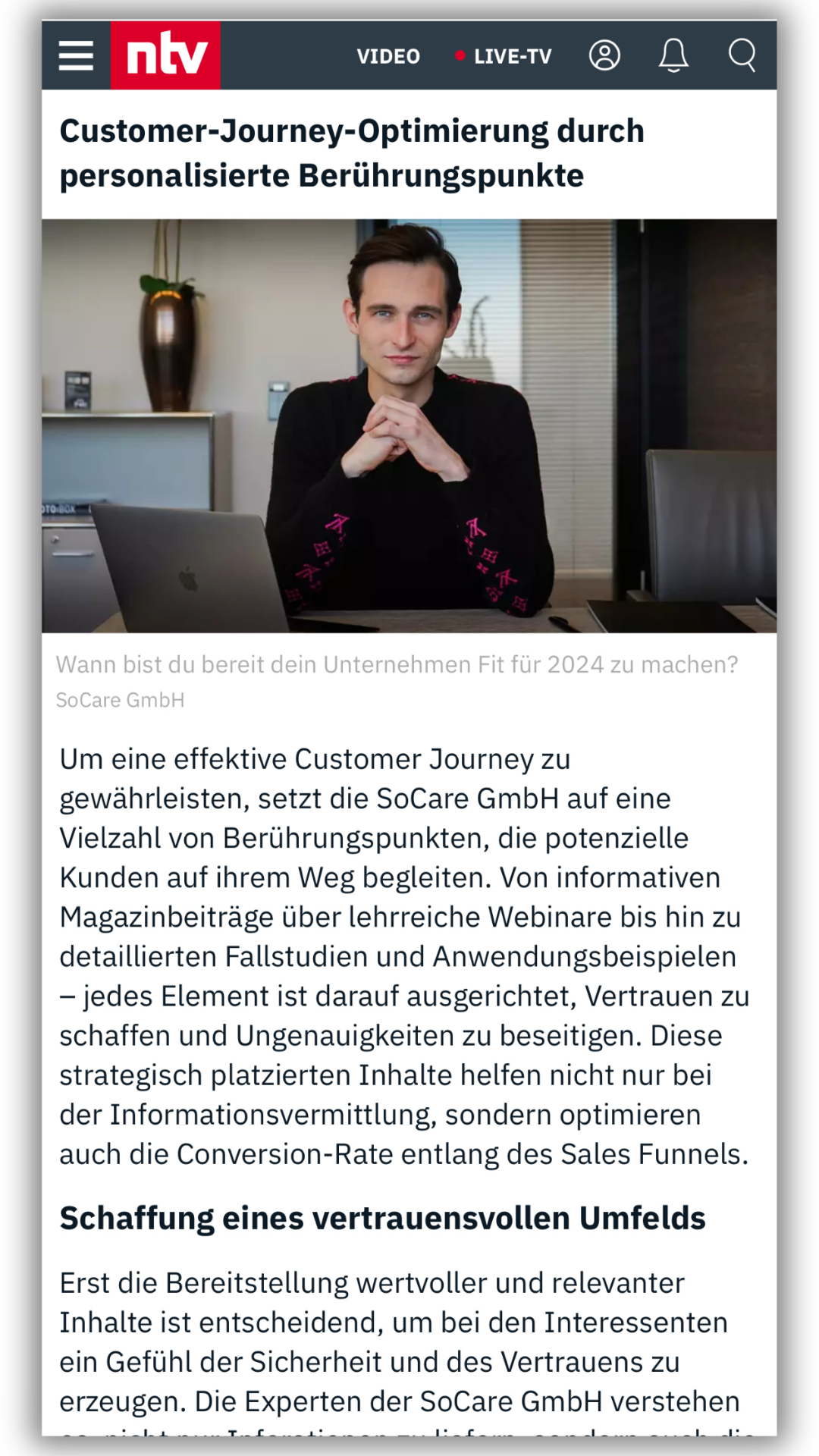
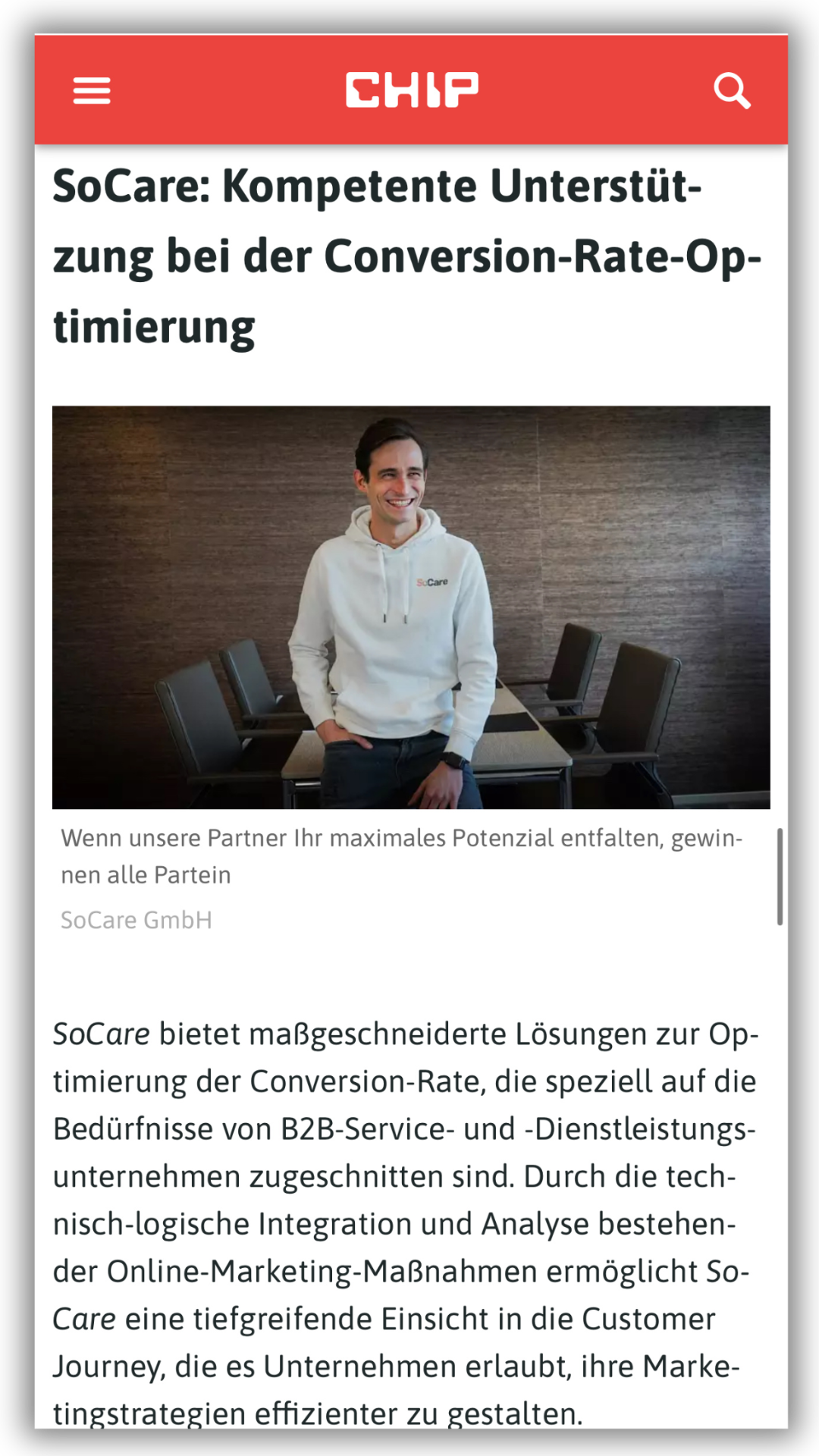
Du willst den Beitrag lieber hören? Kein Problem! Wir haben dir hier eine Audioversion von Unindexed Pages bereitgestellt:
Unindexed Pages: Der umfassende Guide für erfolgreiches Google-Online-Marketing
In der Welt des Online-Marketings dreht sich alles um Sichtbarkeit. Wer bei Google und Co. nicht gefunden wird, existiert im digitalen Raum praktisch nicht. Doch während viele Webseitenbetreiber mit Herzblut an Content, Design und Nutzerführung arbeiten, gibt es ein oft unterschätztes Problem: Unindexed Pages – also Seiten, die von Google nicht indexiert wurden.
In diesem umfassenden Guide erklären wir dir als absolutem Einsteiger Schritt für Schritt, was Unindexed Pages eigentlich sind, warum sie entstehen, welche Arten es gibt, welche Rolle sie in deiner SEO-Strategie spielen und wie du effektiv damit umgehst. Ziel dieses Artikels ist es, dir fundiertes Wissen zu vermitteln – klar, verständlich und vollständig SEO-optimiert.
Was sind Unindexed Pages? – Definition und Bedeutung im Google-Marketing
Der Begriff Unindexed Pages bezieht sich auf Webseiten oder einzelne Unterseiten, die nicht im Index von Suchmaschinen wie Google enthalten sind. Das bedeutet: Wenn jemand einen Suchbegriff bei Google eingibt, werden diese Seiten nicht in den Suchergebnissen (SERPs) angezeigt – selbst dann nicht, wenn der Inhalt eigentlich relevant wäre.
Google „kennt“ diese Seiten nicht, entweder weil es sie noch nie gecrawlt hat oder weil sie bewusst oder unbeabsichtigt vom Index ausgeschlossen wurden. Für viele Website-Betreiber kann dies ein ernsthaftes Problem sein, da jede unindexierte Seite eine verpasste Chance ist, potenzielle Besucher – und damit Kunden – zu erreichen.
Arten von Unindexed Pages: Diese Typen solltest du kennen
Es gibt verschiedene Arten von Unindexed Pages, die unterschiedliche Ursachen und Auswirkungen haben. Grundsätzlich lassen sich folgende Typen unterscheiden:
1. Technisch blockierte Seiten
Diese Seiten werden durch technische Einstellungen wie robots.txt oder das noindex-Meta-Tag bewusst vom Crawling oder Indexieren ausgeschlossen. Sie sind zwar abrufbar, aber Google ist angewiesen, sie zu ignorieren.
2. Nicht gecrawlte Seiten
Google hat diese Seiten (noch) nicht entdeckt, oft weil sie nicht intern verlinkt oder über die Sitemap erreichbar sind. Das Crawling-Budget – also wie viele Seiten Google in einer Sitzung besucht – spielt hier ebenfalls eine Rolle.
3. Duplikat-Inhalte
Seiten mit duplicate content oder sehr ähnlichem Content werden von Google häufig nicht indexiert, weil der Mehrwert für die Suchmaschine fehlt.
4. Thin Content Seiten
Inhalte mit sehr geringem Mehrwert, z. B. automatisch generierte Texte, Seiten mit nur einem Absatz oder leeren Platzhaltern, können ebenfalls von der Indexierung ausgeschlossen werden.
5. Spam- oder Penalty-Seiten
Seiten, die gegen Googles Richtlinien verstoßen, z. B. durch Keyword-Stuffing oder gekaufte Backlinks, können manuell oder algorithmisch aus dem Index entfernt werden.
Wie funktioniert die Indexierung bei Google? – Der Prozess hinter Unindexed Pages
Um zu verstehen, wie Unindexed Pages entstehen, musst du wissen, wie der Google-Index überhaupt funktioniert.
- Crawling: Google schickt sogenannte Crawler (z. B. Googlebot) los, um das Internet nach neuen und aktualisierten Inhalten zu durchsuchen.
- Rendering: Die Crawler analysieren die Seitenstruktur, HTML-Code, JavaScript und Inhalte.
- Indexierung: Google entscheidet, ob und wie eine Seite in den Index aufgenommen wird. Dabei wird sie katalogisiert und mit passenden Keywords versehen.
- Ranking: Nur indexierte Seiten können bei Suchanfragen gerankt werden.
Unindexed Pages entstehen also entweder, weil sie im Schritt 3 übersprungen werden, oder weil sie im Nachhinein entfernt wurden – durch technische Anweisungen oder algorithmische Filter.
Wer sind die wichtigsten Akteure bei Unindexed Pages?
Im Zusammenspiel rund um Unindexed Pages sind mehrere Gruppen beteiligt:
Website-Betreiber und SEOs sind verantwortlich für die technische Struktur, die Inhalte und die Indexierungsanweisungen. Sie entscheiden bewusst oder unbewusst, ob eine Seite indexiert werden kann.
Googlebot – der Webcrawler von Google – ist der technische Akteur, der entscheidet, ob eine Seite überhaupt besucht und analysiert wird.
Google Search Console ist das wichtigste Tool zur Kommunikation zwischen Website-Betreibern und Google. Sie zeigt Indexierungsprobleme und Crawling-Fehler transparent auf.
Welche Ziele können mit Unindexed Pages verfolgt werden?
Der gezielte Umgang mit Unindexed Pages verfolgt im professionellen Google-Marketing ganz klare Ziele. Zum einen geht es darum, die Qualität der indexierten Inhalte zu erhöhen, indem unwichtige, doppelte oder irrelevante Seiten aus dem Index ausgeschlossen werden. So konzentriert sich Google beim Crawling und Indexieren auf die Seiten, die für das Ranking und den Nutzer tatsächlich einen Mehrwert bieten. Ein weiteres Ziel ist es, die Struktur und Steuerung der Sichtbarkeit einer Website gezielt zu lenken – etwa durch das bewusste Verhindern der Indexierung von Login-Seiten, internen Suchergebnissen oder sensiblen Inhalten wie Bestellbestätigungen. Darüber hinaus ermöglichen bewusst unindexierte Seiten eine effizientere Nutzung des sogenannten Crawling-Budgets, besonders bei großen Webseiten mit Tausenden von URLs. Ziel ist es immer, dass Google möglichst ressourcenschonend auf die hochwertigen Inhalte zugreifen kann, während irrelevante Seiten ignoriert werden.
Vorteile von Unindexed Pages – Wenn gezielte Kontrolle sinnvoll ist
Der strategische Einsatz von Unindexed Pages bietet Unternehmen eine Reihe wertvoller Vorteile im SEO-Kontext. Zunächst trägt er dazu bei, die Relevanz und Qualität des Google-Indexes zu verbessern, indem nur die besten, relevantesten Inhalte für die Suchmaschinen sichtbar gemacht werden. Das wirkt sich direkt auf die Wahrnehmung der Domainqualität aus und kann langfristig das Ranking positiver beeinflussen. Unternehmen können so ihre SEO-Strategie präziser steuern, etwa indem sie gezielt nur optimierte Landingpages indexieren lassen und gleichzeitig dünne oder doppelte Inhalte ausblenden. Dies hilft, potenzielle Rankingverluste durch Duplicate Content zu vermeiden. Ein weiterer Vorteil liegt im Schutz sensibler Informationen: Interne oder vertrauliche Seiten können bewusst von der Indexierung ausgeschlossen werden, was die Datensicherheit stärkt und rechtliche Risiken minimiert. Unindexed Pages sind damit ein effektives Instrument, um sowohl die technische als auch strategische Effizienz einer Website zu verbessern.
Herausforderungen: Was bei Unindexed Pages schieflaufen kann
Trotz ihrer Vorteile können Unindexed Pages für Website-Betreiber auch eine Reihe ernsthafter Herausforderungen mit sich bringen – vor allem dann, wenn sie ungewollt auftreten. Eine der häufigsten Schwierigkeiten besteht darin, dass wichtige Seiten, wie beispielsweise zentrale Produkt- oder Dienstleistungsseiten, versehentlich durch falsche Meta-Tags oder robots.txt-Einträge vom Index ausgeschlossen werden. Ebenso problematisch ist es, wenn Google bestimmte Seiten nicht crawlt, weil sie nicht intern verlinkt oder nur über JavaScript erreichbar sind – ein technischer Fehler, der im Hintergrund bleiben kann, solange er nicht aktiv überwacht wird. Auch die Erkennung von Duplicate oder Thin Content kann herausfordernd sein, vor allem bei großen Seitenstrukturen, bei denen automatisch generierte Inhalte oder Filterkombinationen häufig entstehen. Darüber hinaus ist die Kontrolle über den Google-Index ein dynamischer Prozess, bei dem Inhalte regelmäßig aktualisiert, gelöscht oder hinzugefügt werden – und jede Veränderung potenziell neue Indexierungsprobleme mit sich bringen kann. Ohne kontinuierliches Monitoring und die richtigen Tools laufen Unternehmen Gefahr, Sichtbarkeit und Rankings einzubüßen, ohne es sofort zu bemerken.
In welchen Branchen spielt das Thema Unindexed Pages eine besondere Rolle?
Unindexed Pages spielen in nahezu allen Online-Branchen eine Rolle, doch in einigen Industriezweigen sind sie besonders entscheidend für den SEO-Erfolg. Im E-Commerce zum Beispiel, wo Unternehmen oft tausende von Produktseiten, Filteroptionen und Varianten bereitstellen, ist es essenziell, genau zu steuern, welche Seiten im Google-Index erscheinen sollen. Hier geht es darum, doppelte oder inhaltsarme Seiten gezielt auszuschließen, um den Fokus auf leistungsstarke Kategorien und Top-Produkte zu legen. Auch in der Verlags- und Nachrichtenbranche, wo täglich große Mengen an Content produziert werden, ist die Indexierungsstrategie entscheidend: Alte oder irrelevante Artikel müssen effizient aus dem Index entfernt werden, um Crawling-Budgets optimal zu nutzen. Im Dienstleistungsbereich, insbesondere bei lokalen Unternehmen mit vielen Standortseiten (z. B. Ärzte, Friseure, Handwerker), gilt es, ähnliche Landingpages so zu strukturieren, dass sie sinnvoll indexiert werden – ohne Google durch Redundanzen zu verwirren. Selbst im B2B-Bereich, bei Softwarefirmen oder Agenturen, sind Unindexed Pages von Bedeutung, etwa um Whitepaper-Downloads, interne Demos oder dynamisch generierte Seiten bewusst aus der öffentlichen Suche herauszuhalten.
Beispiele für erfolgreiche Anwendung von Unindexed Pages
Ein bekannter Onlinehändler wie Zalando setzt gezielt auf die Steuerung von Indexierungen. Filterkombinationen („blaue Sneaker Größe 43“) werden nicht indexiert, um Duplicate Content zu vermeiden. Stattdessen wird nur eine optimierte Hauptkategorieseite indexiert.
HubSpot, ein Softwareunternehmen im B2B-Bereich, nutzt gezielt Noindex-Tags für Whitepaper-Downloadseiten oder Tracking-URLs, um keine internen Prozesse im Index sichtbar zu machen.
Tools zur Analyse und Optimierung von Unindexed Pages
Der professionelle Umgang mit Unindexed Pages erfordert verlässliche Tools, die den Indexierungsstatus überwachen, analysieren und Optimierungspotenzial aufdecken. Allen voran steht hier die Google Search Console – das zentrale Interface zwischen Website und Google. Sie bietet einen umfassenden Einblick in die Indexabdeckung, meldet Gründe für Ausschlüsse (wie noindex, Crawling-Fehler oder Weiterleitungen) und erlaubt die manuelle URL-Überprüfung. Für tiefere technische Analysen greifen viele SEO-Experten auf den Screaming Frog SEO Spider zurück. Dieses Tool crawlt komplette Websites und zeigt strukturiert, welche Seiten indexiert, blockiert oder falsch verlinkt sind. Ebenfalls hilfreich sind Tools wie Ahrefs oder SEMrush, die aufzeigen, welche Seiten tatsächlich organischen Traffic generieren und wie der Status aus Sicht der Suchmaschine ist. Auch spezialisierte Lösungen wie Sitebulb oder Oncrawl bieten tiefergehende Funktionen, insbesondere bei sehr großen Domains. In der Kombination liefern diese Tools wertvolle Daten, um Unindexed Pages entweder gezielt zu identifizieren – oder sie bewusst zu erzeugen.
Aktuelle Trends im Bereich Unindexed Pages
Im Zuge der stetigen Weiterentwicklung von Suchalgorithmen und Webtechnologien verändern sich auch die Herausforderungen und Chancen im Umgang mit Unindexed Pages. Einer der auffälligsten Trends ist der zunehmende Einsatz von künstlicher Intelligenz in SEO-Tools, die automatisch erkennen, welche Seiten indexiert werden sollten – und welche potenziell schädlich für die SEO-Leistung sind. Ebenso entwickelt sich die JavaScript-Indexierung weiter: Google kann heute zwar viele clientseitig gerenderte Inhalte erkennen, doch fehlerhafte oder überladene JS-Umgebungen führen nach wie vor häufig zu unbeabsichtigten Unindexed Pages. Auch der Trend zu Mobile-First-Indexierung ist nicht zu unterschätzen – denn wenn die mobile Version einer Seite technisch nicht sauber umgesetzt ist, wird sie im schlimmsten Fall überhaupt nicht indexiert, selbst wenn die Desktop-Version einwandfrei wäre. Daneben gewinnt das Thema Crawling-Budget-Optimierung zunehmend an Bedeutung, vor allem bei großen, dynamischen Webseiten. Wer sein Indexierungsmanagement nicht im Griff hat, riskiert, dass Google nur einen Bruchteil der relevanten Seiten erfasst. Neue Tools und Algorithmen helfen dabei, die Effizienz der Indexierung zu steigern – ein Thema, das 2025 mehr denn je über den SEO-Erfolg entscheiden kann.
Fazit: Warum Unindexed Pages ein zentrales Thema im Google-Online-Marketing sind
Unindexed Pages sind kein Randthema – sie sind zentral für deine SEO-Performance. Nur indexierte Seiten können in den Suchergebnissen erscheinen und so potenzielle Kunden auf deine Seite bringen. Jede nicht indexierte Seite ist entweder eine verpasste Chance oder ein bewusster Schritt zur Qualitätskontrolle.
Für Anfänger ist es wichtig, den Unterschied zwischen „gewollt“ und „ungewollt“ unindexierten Seiten zu verstehen – und sich die richtigen Tools zur Hilfe zu nehmen. Wer sein SEO ernst nimmt, sollte regelmäßig prüfen, welche Seiten indexiert sind, welche nicht – und warum.
Häufig gestellte Fragen zu Unindexed Pages
Was bedeutet „Unindexed Page“ bei Google?
Eine „Unindexed Page“ ist eine Webseite, die nicht im Google-Index enthalten ist und somit nicht in den Suchergebnissen erscheint.
Wie finde ich heraus, ob eine Seite indexiert ist?
Nutze die Google Search Console oder gib site:deineseite.de/url in Google ein – erscheint kein Treffer, ist die Seite nicht indexiert.
Warum wird meine Seite nicht indexiert?
Häufige Gründe sind noindex-Tags, Blockierungen durch robots.txt, technischer Fehler oder unzureichender Content.
Wie kann ich eine Seite zur Indexierung anmelden?
Über die Google Search Console kannst du eine URL direkt zur Indexierung einreichen.
Sind Unindexed Pages schlecht für SEO?
Nicht zwangsläufig. Bewusst eingesetzte Unindexed Pages helfen dabei, den Fokus auf hochwertige Inhalte zu legen.
Was ist der Unterschied zwischen Crawling und Indexierung?
Crawling bedeutet, dass Google eine Seite besucht. Indexierung heißt, dass sie in den Suchergebnissen erscheint.
Was ist ein Noindex-Tag?
Ein HTML-Tag (<meta name=”robots” content=”noindex”>), der Google anweist, eine Seite nicht zu indexieren.
Wie lange dauert es, bis Google eine Seite indexiert?
Das kann zwischen wenigen Stunden und mehreren Wochen dauern – abhängig von Domain-Autorität, Verlinkung und technischem Zustand.
Kann ich sehen, welche Seiten meiner Website nicht indexiert sind?
Ja, über die Indexabdeckung in der Google Search Console.
Kann zu viele Unindexed Pages ein SEO-Problem sein?
Ja, vor allem wenn wichtige Inhalte nicht indexiert sind oder die Seitenstruktur das Crawling erschwert.